最近项目需要设计订单模块,其中首当其冲的就是订单号的设计。本文整理部分订单号设计思路,抛砖引玉。
设计要求
- 唯一性 订单号不能重复
- 安全性 外部人员不能通过订单号窥探到订单业务数据,比如:SKU 订单数等。
- 可读性(可选) 内部人员可以比较直观的看出订单所属商家,品类等信息。
设计思路
数据库自增ID
优点:
- 由于自增,唯一性条件满足。又因为是主键,查询效率也很高,且支持范围查询。
缺点:
- 不满足安全性,自增ID可以直接看到订单数量。没有业务字段参与其中,没有可读性。
UUID
优点:
- 在同一台机器上生产订单号(多台机器可能出现碰撞),满足唯一性条件。
- 数据无意义,谁也不能猜到业务数据。安全性满足。
缺点:
- 数据比较长(36位),没有可读性。
在不考虑可读性的情况下,UUID 也还是不错的。各个语言都有成熟的库,使用方便。
SnowFlake(雪花算法)
SnowFlake 使用 int64 数字做唯一ID,且 ID 引入时间戳,保持自增性且不重复。
雪花算法结构:
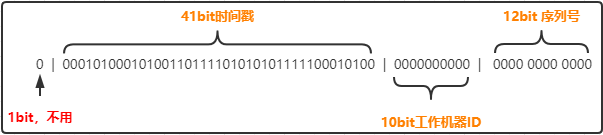
优点:
- 数据格式紧凑,数据库使用 bigint 即可存储
- ID保持自增性,满足唯一性。
- 支持分布式生成。
缺点:
- 可读性较差
其实也可以将业务数据放进去,比如从工作机器中抽个几位标识业务字段。
转为二进制也可解出业务数据。
自定义组合
假设订单号需包含:订单类型、商品大类ID、日期、用户ID。
简单组合
订单类型(1位) 商品大类ID(2位) 日期(10位) 用户ID(后4位)
1 22 1625133028 9527订单号即:1226251330289527,长度16位。
这样也比较容易看出规律,需要将数据变形,比如将数据反过来显示,具体实现自行思考吧。
总结
订单号设计还是需要根据具体业务来设计。如果不考虑可读性,雪花算法就挺好。
参考: